最近,DeepSeek的低成本训练方法引发了广泛讨论。一些人担心,这种技术突破可能会减少对GPU的需求,从而对GPU市场造成负面影响。
前百度高级科学家Junde Wu认为,事实可能恰恰相反。DeepSeek的创新不仅没有削弱GPU市场,反而为其带来了新的机遇。
误解一:低成本训练意味着GPU需求减少
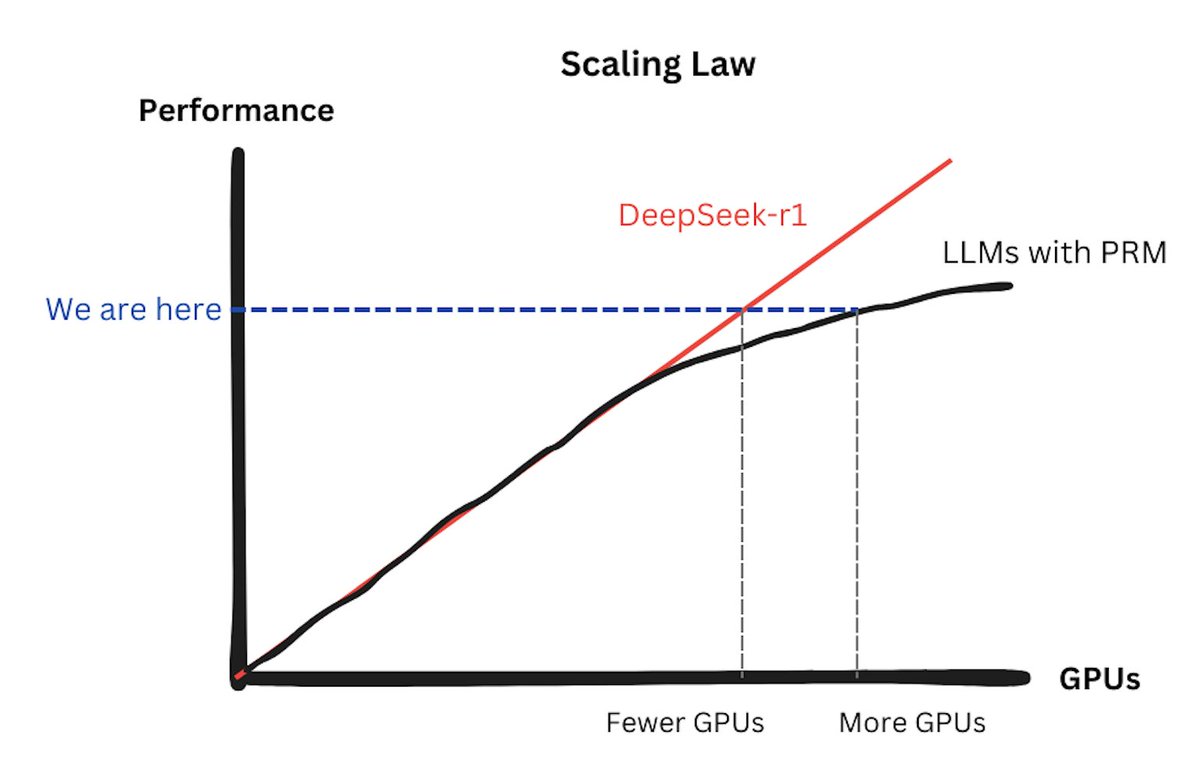
有人认为,DeepSeek的低成本训练方法会让公司减少对GPU的依赖。然而,这种观点忽略了一个关键事实:DeepSeek-R1的训练方法是可扩展的。换句话说,增加更多的GPU仍然可以显著提升模型性能。DeepSeek实际上改进了扩展定律(Scaling Laws),使其重新发挥作用。
在DeepSeek之前,大型模型使用过程奖励模型(PRMs)时,往往会遇到收益递减的问题。扩展定律几乎失效,因为训练PRMs需要额外的GPU资源来支持推理监督。而DeepSeek通过优化训练方法,重新激活了扩展定律:投入的GPU越多,性能提升越显著。这对GPU市场来说无疑是一个好消息。
误解二:DeepSeek只关注推理,而非训练
另一个常见的误解是,DeepSeek主要关注推理(inference)而非训练(training)。实际上,DeepSeek-R1的核心正是训练——它采用了一种称为**后训练(post-training)**的方法,旨在提升模型的推理能力。这种训练方式在GPU需求上与预训练(pretraining)并无太大差异。
至于纯推理时的扩展/搜索(即模型尝试不同答案并选择最佳结果),目前并不常见,因为它会显著增加用户延迟。尽管DeepSeek发现PRMs在推理后训练中作用有限,但在测试时推理中可能有一定价值。然而,这种方法的成本效益比仍然较低,因此并未被广泛采用。
从长远来看,GPU市场和扩展定律的真正威胁并非来自模型本身,而是数据的枯竭。大型语言模型(LLMs)已经消耗了互联网上的大部分可用数据,未来获取更多高质量数据的难度将越来越大。最终,我们可能会面临一个尴尬的局面:拥有大量GPU,却无数据可训练。
DeepSeek的低成本训练方法不仅没有削弱GPU市场,反而通过改进扩展定律和优化训练流程,为GPU需求注入了新的动力。尽管数据枯竭可能成为未来的长期挑战,但在可预见的未来,GPU仍然是AI训练和推理的核心硬件。
DeepSeek的成功提醒我们,技术创新并非零和游戏。通过优化算法和硬件协同,我们可以实现更高效、更经济的AI训练,同时为整个行业创造新的机遇。对于GPU市场来说,这无疑是一个值得期待的未来。

 大存
2025/03/11 02:10
大存
2025/03/11 02:10
 以太坊信徒
2025/02/14 02:56
以太坊信徒
2025/02/14 02:56




